A comparison between RISC-V implementations

This article seeks to perform a comparison among the main implementations of RISC-V, which are the chips: Rocket, BOOM, Ariane (CVA6), and SHAKTI C-Class.
Introduction
RISC-V is a new Instruction Set Architecture (ISA) that originated as a research and education project at the University of California, Berkeley. It has been gaining more and more industry implementations. It was developed with the aim of being open, free, and accessible, allowing anyone to use, modify, and implement the architecture without restrictions or additional costs. The ISA was designed to support 32-bit, 64-bit, and 128-bit address spaces, aiming to enhance its adoption.
This flexibility allows the RISC-V architecture to be used across a wide range of applications, from low-power devices to high-performance systems. By accommodating different word sizes, the RISC-V ISA offers greater versatility to meet the specific requirements of each project, enabling efficient utilization of available resources. This modular approach contributes to the popularity and growing acceptance of the RISC-V architecture in various industries and sectors.
RISC-V is an architecture that allows individuals and organizations to create their own implementations. Due to this fact, the purpose of this article is to introduce and compare the main implementations. It consists of three sections: first, the implementations will be presented, followed by the comparison, and finally, the conclusion.
Implementation
For the selection of implementations to be presented, robust and advanced implementations were researched, ones capable of running an Operating System (OS) on an FPGA board. For this scenario, the following choices were made: Ariane (CVA6)[4], Boomv3[5], Rocket[1], and Shakti C-Class[2].
Rocket Chip*
The Rocket Chip is a processor development project that was created at the University of California, Berkeley. It plays a significant role as an initial implementation and serves various purposes within the field of computing. The primary objective of the Rocket Chip is to act as a kind of reference model for processors based on the RISC-V Instruction Set Architecture (ISA). The Rocket Chip serves several key functions: it’s a reference for RISC-V processors, an open-source library, and a testing platform for new ideas and developments related to processors.
It’s an in-order scalar processor with a 5-stage pipeline, meaning it’s a type of central processing unit in a computer. In-order refers to executing one instruction at a time, and the 5-stage pipeline refers to the steps the processor follows to execute each instruction. These steps are divided into five distinct stages: fetch (retrieve the next instruction), decode (understand what the instruction does), execute (perform the instruction’s operation), memory access (handle stored information), and write-back (update results).
Pipeline
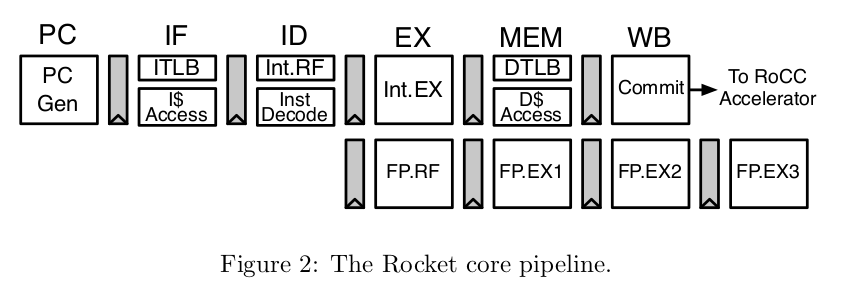
It features a classic 5-stage pipeline, as described earlier. It includes a temporary storage area (cache) for data and instructions, which can be either fast or slower. The L1 and L2 cache types can be adjusted as needed. To predict where a branch (a type of decision) should go, it employs a set of configurable resources, like a crystal ball, including a Branch Target Buffer (BTB), a Branch History Table (BHT), and a Return Address Stack (RAS) – a list of places it can go back to after making a decision.
Furthermore, there’s a component called the Translation Lookaside Buffer (TLB), which helps translate codes and data into information that the processor can quickly understand, ultimately aiding in making the computer run faster overall.
BOOMv3 (SonicBOOM)*
BOOMv3, also known as SonicBOOM, is a processor project developed by the University of California, Berkeley. It’s designed to be superscalar out-of-order, which means it can execute multiple instructions in parallel, regardless of the order they were written in the program. This typically results in high performance, as it allows the processor to make better use of available resources.
The BOOMv3 pipeline consists of 10 stages, which means instructions go through a series of separate steps as they’re processed. This helps break down the work into smaller parts and increases the efficiency of the processor. However, when a branch misprediction occurs, there’s a penalty of 12 cycles, meaning the processor might need extra time to recover from an error.
The BOOMv3 project is considered ambitious, as it’s intended for high-performance computing. It’s especially suitable for use in computer clusters and servers where processing power is critical. Clusters are sets of interconnected computers that work together to handle complex tasks, and servers are dedicated computers providing services like web hosting or data storage. Therefore, BOOMv3 is optimized to handle intensive workloads and is a popular choice for scenarios where performance is paramount.
Pipeline
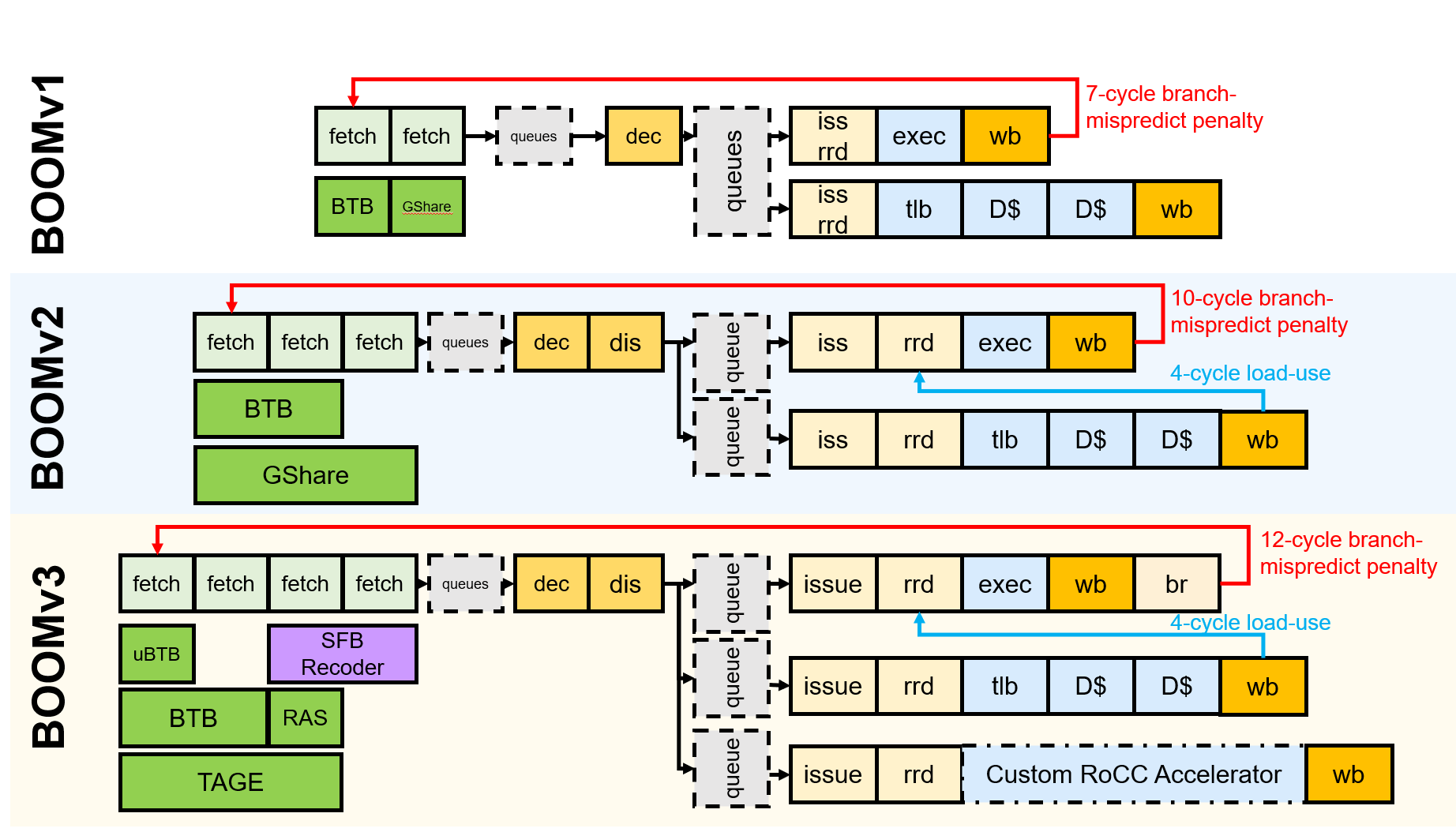
BOOM features a pipeline that can be described as complex and robust. This means it’s capable of effectively managing diverse and challenging tasks. BOOM is also configurable and customizable, allowing developers to tailor the processor according to the specific needs of their applications.
An important detail is the TLB (Translation Lookaside Buffer), which helps translate codes and instructions into information that the processor can understand more quickly, enhancing overall performance. Another notable feature of BOOM is its approach to branch predictions (decisions on which path a program will follow). It employs complex two-level predictors based on global history vectors, known as GShare or TAGE. These predictors act as a kind of guessing machine that helps the processor anticipate branching decisions, improving efficiency.
BOOM also supports full branch speculation. This means it can make risky decisions about paths to take and correct them if those decisions turn out to be wrong. This is accomplished using a set of resources, including the BTB (Branch Target Buffer), the BHT (Branch History Table), the TLB, and the RAS (Return Address Stack).
Furthermore, there’s a component called uBTB (micro Branch Target Buffer), also known as next-line-predictor or L0 BTB. This works as a shortcut for small loops, quickly redirecting the next instruction address, which significantly enhances execution speed in specific situations.
Ariane (CVA6)*
CVA6 is a processor implementation developed by the HW group, a global organization dedicated to creating open-source and free hardware. This signifies that the CVA6 project is accessible to everyone, allowing individuals to study, modify, and use it as needed.
It’s a superscalar out-of-order processor, which means it can execute multiple instructions simultaneously and not necessarily in the order they were written in the program. It features a 6-stage pipeline and can be compared to the Rocket Chip pipeline, which has 5 stages, but with an additional stage for the Program Counter (PC). The Program Counter is a special register that stores the address of the next instruction to be executed.
In the case of CVA6, this process is treated as a separate phase in the pipeline, which can bring advantages in terms of efficiency and performance. This approach of incorporating the PC process as a pipeline stage is a distinctive feature of CVA6, potentially positively influencing the overall processor performance in certain usage scenarios.
Pipeline
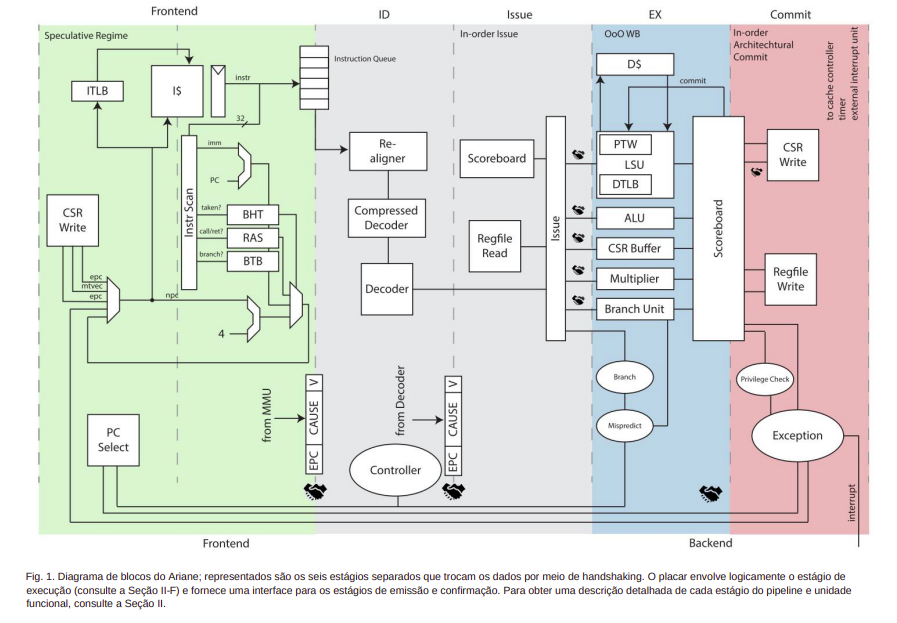
Ariane (CVA6) is adaptable to demand and equipped with specialized components to enhance various key tasks. One of its distinctive parts is the PTW (Page Table Walker), which acts as an intelligent translator. When an address is not found in the TLB (Translation Lookaside Buffer), the PTW comes into action. It functions as a versatile guide that queries main memory, performing the translation from virtual to physical address and subsequently adding the corresponding entry into the TLB. Its role is crucial in expediting the memory access process, optimizing information retrieval efficiency.
Another notable aspect is its branch prediction capability. This prediction mechanism is supported by a set of resources, including the BTB (Branch Target Buffer), which acts as a pointer to potential choices. Additionally, the BHT (Branch History Table) functions like a diary, recording previous patterns of decisions, contributing to a more precise approach. Complementing this functionality, the TLB and the RAS (Return Address Stack) also play fundamental roles in preparing for future events, enabling more efficient and predictable processing.
Shakti C-Class*
SHAKTI is an open-source project initiated by the Indian Institute of Technology Madras. Its aim is to create advanced processors that are accessible and customizable for various applications. The C-Class is one of the members of the SHAKTI processor family. This processor family seeks to provide diverse options for different needs. The C-Class processor is a notable example within this family. It is an in-order scalar type and features a 5-stage pipeline.
What makes it even more special is that it’s the most advanced member of the SHAKTI processor lineup. This signifies that it incorporates the latest enhancements and features developed by the project’s team. It represents the pinnacle of evolution within this processor line, ensuring enhanced performance and more sophisticated capabilities.
Pipeline
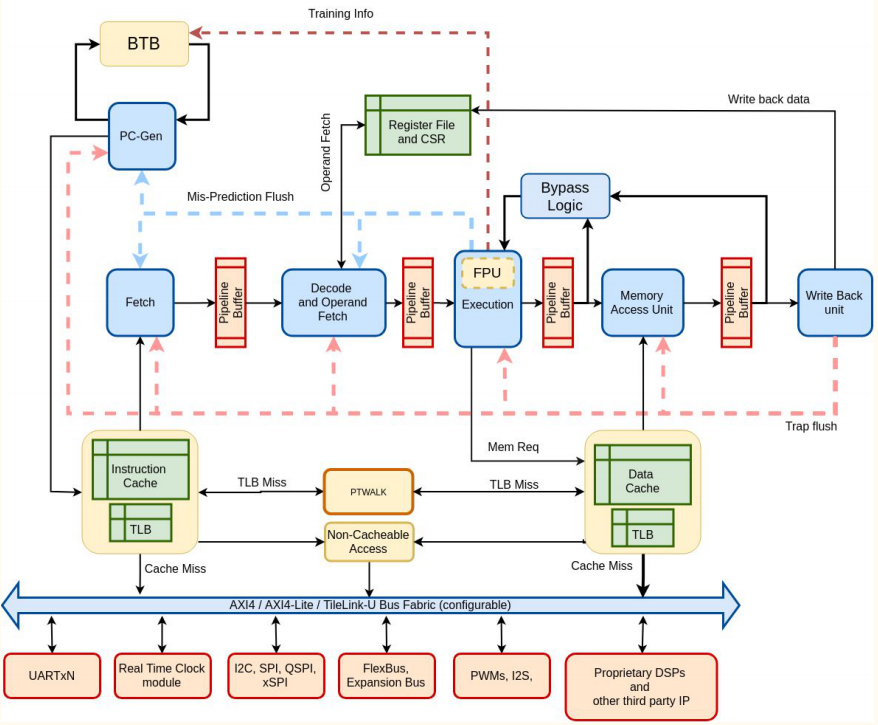
Based on the implementations mentioned earlier, this processor exhibits the most essential and foundational characteristics. Its pipeline adopts a straightforward 5-stage approach, employing classic structures to optimize processing. In the realm of branch prediction, it benefits from the capabilities of BTB, BHT, and RAS, tools that work together to anticipate branching choices and optimize execution.
A notable feature is that this processor has separate L1 caches, serving as temporary storage areas for frequently used data, contributing to quicker and more efficient access. Additionally, its separate associative TLBs play the role of translating virtual addresses into physical memory addresses, further optimizing overall performance.
This processor stands out for its simplicity compared to the previous implementations, making it more streamlined in its operations. It is considered the most elementary among the processors mentioned earlier. Flexibility is also a key characteristic, as it can be configured and adapted according to needs, allowing specific adjustments for different scenarios.
Comparison
| Rocket | BOOMv3 | Ariane | C-Class | |
|---|---|---|---|---|
| Bits | 32/64 | 64 | 64 | 32/64 |
| Stages | 5 | 10/12 | 6 | 5 |
| Funct. Units | 4 | 8 | 6 | 3 |
| DMIPS | 1,71 MHz | 3,87 MHz | 1,21 MHz | 1,70 MHz |
| Tech | 45nm | 45nm | 22 nm | 22 nm |
| Speed | 1,6 GHz | 1,5 GHz | 1,7 GHz | 0,8 GHz |
| Area | 0,5 mm² | 1,7 mm² | 0,3 mm² | 0,29 mm² |
| Power | 125 mW | 300 mW | 52 mW | 90 mW |
Initially, we can observe the common characteristics between them. Both have support for 64-bit architecture. Furthermore, they implement versions close to the classic 5-stage pipeline and incorporate branch prediction in their implementations, utilizing resources like BTB, BHT, and RAS. Additionally, they are configurable, and their caches are accompanied by TLBs.
Using the parameter of reported DMIPS/MHz quantity, the literature considers BOOMv3 to lead the performance criterion per MHz and surpass all others by more than a factor of 2. It’s important to note that this doesn’t necessarily mean it’s the fastest processor, but rather that it executes more instructions per clock cycle. Following in sequence, the Rocket, C-Class, and CVA6 processors follow the mentioned order. The latter achieve similar values, with the exception of Ariane.
According to the chipset reference, Ariane reaches a rate of 1.70 GHz, while the literature indicates its actual rate to be 1.21 GHz, putting it at a disadvantage compared to its competitors. Thus, Ariane has the lowest rate among the compared models.
BOOMv3 also stands out as the most complex implementation, with a larger silicon area and higher power consumption. This is a result of its superscalar structure, parallelism, and execution capability. However, it’s important to note that four Rocket cores could fit into a single BOOMv3 core, which applies to other implementations as well. Depending on the design, multiple low-power cores might be more advantageous than a highly efficient core.
The chip technology can justify the area and consumption of these processors. Rocket and BOOMv3 are manufactured using 45 nm, while Ariane and C-Class use 22 nm. This choice of technology has a direct impact on energy consumption and the chip’s footprint. Smaller values result in lower energy requirements and greater space efficiency within the chip. With more advanced technologies, chips can be reduced in size.
Another interesting point is that Ariane and C-Class manage to be smaller and consume less than half the energy of Rocket, making them ideal for projects with minimal consumption requirements. Thus, they are compact and efficient implementations. Ariane also stands out in terms of efficiency and performance.
Additionally, it’s important to note that, with the exception of C-Class, all implementations present similar processing speeds.
Conclusion
All implementations have their advantages and disadvantages, catering to diverse audiences with specific needs.
The Rocket implementation stands out for its pioneering nature, simplicity, and efficiency. Being the first implementation, it serves as the ISA debugger, shaping and referencing the emergence of new boards. Additionally, it is favored in academic publications.
BOOMv3 stands out for being the most robust and efficient implementation, tailored for high-performance computing and its demands.
Ariane, on the other hand, stands out for its compact size and energy efficiency. It was designed to meet more constrained development requirements.
Lastly, the C-Class core is designed for medium-scale computing systems and possesses suitable characteristics for that purpose. Its approach is simple and efficient.
References
[1] Krste Asanović et al.2016.The Rocket Chip Generator. TechnicalReport UCB/EECS-2016-17. Department of Electrical Engineering &Computer Sciences, University of California, Berkeley, CA, USA.
[2] Gurajala Bhavitha Chowdary. 2022.Set Associative Data TLB for ShaktiC-Class Processor. Ph. D. Dissertation. Indian Institute of TechnologyMadras.
[3] Alexander Dörflinger, Mark Albers, Benedikt Kleinbeck, Yejun Guan,Harald Michalik, Raphael Klink, Christopher Blochwitz, Anouar Nechi,and Mladen Berekovic. 2021. A comparative survey of open-sourceapplication-class RISC-V processor implementations. InProceedings ofthe 18th ACM International Conference on Computing Frontiers. ACM. https://doi.org/10.1145/3457388.3458657
[4] Florian Zaruba and Luca Benini. 2019. The Cost of Application-ClassProcessing: Energy and Performance Analysis of a Linux-Ready 1.7-GHz 64-Bit RISC-V Core in 22-nm FDSOI Technology.IEEE Transac-tions on Very Large Scale Integration (VLSI) Systems27, 11 (nov 2019),2629–2640. https://doi.org/10.1109/tvlsi.2019.2926114
[5] Jerry Zhao, Ben Korpan, Abraham Gonzalez, and Krste Asanovic. 2020.SonicBOOM: The 3rd Generation Berkeley Out-of-Order Machine.Fourth Workshop on Computer Architecture Research with RISC-V(May2020).
Glossary
- Branch Target Buffer (BTB): Predicts the potential target address for branch instructions based on previous patterns.
- Translation Lookaside Buffer (TLB): It is a small associative memory that stores translations of virtual addresses to physical addresses.
- Cache: It is a fast storage area used to store copies of data that are frequently accessed.
- Page Table Walker (PTW): It is a component of a processor’s memory management unit (MMU). The PTW is responsible for translating virtual addresses into physical addresses.
- Return Address Stack (RAS): It is used to track the program’s execution flow and ensure that the execution flow returns appropriately to the instruction that made the call.
- Branch History Table (BHT): Stores patterns of branch decision history and aids in predicting the likelihood of a branch instruction being taken or not taken.